TurboQuant (Google) : Comment la compression extrême va démocratiser l'IA Locale On-Premise

L'essentiel à retenir : la technologie TurboQuant de Google brise le goulot d'étranglement de la mémoire VRAM en compressant le cache clé-valeur jusqu'à six fois. Cette avancée permet de déployer des IA puissantes sur des serveurs standards sans investissement matériel massif, garantissant souveraineté et sécurité des données en local. Le gain est concret avec une vitesse de calcul multipliée par huit sur NVIDIA H100.
Réduire l'empreinte mémoire d'un modèle par six sans altérer ses performances semble impossible, pourtant TurboQuant Google brise ce plafond de verre technique. Cette innovation de compression transforme votre infrastructure existante en un moteur de déploiement IA entreprise ultra-performant, capable de gérer un LLM local avec une agilité inédite. En résolvant le goulot d'étranglement du cache KV, cette technologie garantit une optimisation VRAM IA maximale pour une IA On-Premise souveraine et enfin accessible.
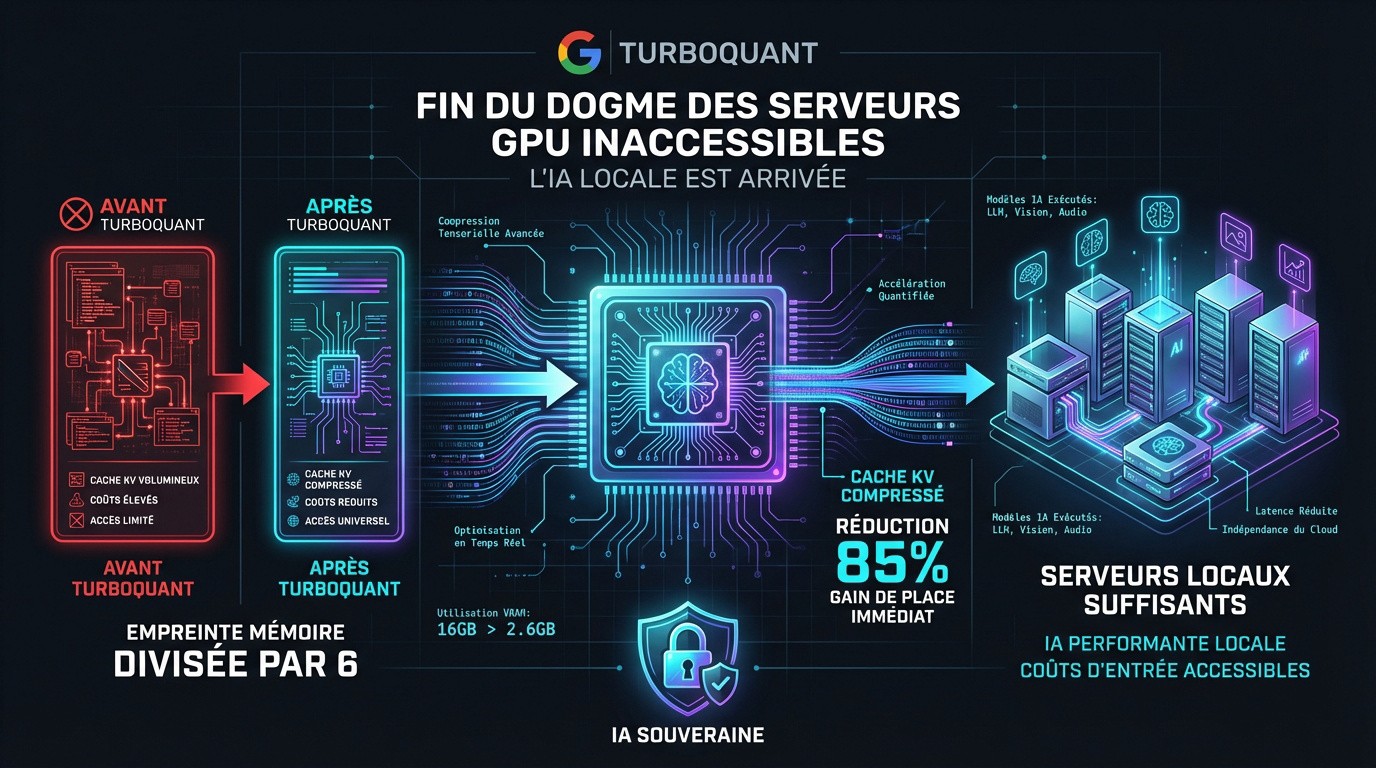
Turboquant Google et la fin du dogme des serveurs gpu inaccessibles
Sécurité absolue et souveraineté sans dépendance au cloud
Puissance de calcul brute sur votre matériel standard en 2026
Turboquant Google et la fin du dogme des serveurs gpu inaccessibles
L'époque où l'IA puissante exigeait des investissements pharaoniques touche à sa fin grâce aux récentes percées de Google.
Le goulot d'étranglement du cache kv enfin brisé
Historiquement, la mémoire VRAM saturait vite à cause du cache clé-valeur. TurboQuant change la donne. Cette solution compresse ces données de manière inédite pour libérer l'infrastructure.
L'empreinte mémoire est divisée par six grâce à cette technique. On traite désormais des contextes très longs sans encombre. Les besoins matériels du serveur n'explosent plus, même avec des modèles massifs.
La fluidité revient enfin dans vos systèmes. Les modèles de langage deviennent légers et agiles.
Réduction de 85% du cache KV
Gain de place immédiat
Compatibilité accrue
Pourquoi vos serveurs actuels suffisent pour l'ia
Oubliez l'achat de clusters GPU massifs et ruineux. La quantification extrême permet aux puces standard de 2026 de briller. Vos machines actuelles font tourner des modèles experts sans broncher.
Comparez les coûts réels. En 2024, le ticket d'entrée était prohibitif pour beaucoup. En 2026, votre infrastructure existante suffit largement pour une IA locale performante et souveraine.
Le matériel dédié hors de prix devient obsolète. Votre parc informatique cache une puissance de calcul insoupçonnée que nous pouvons exploiter dès maintenant.
L'accessibilité financière change tout. L'IA souveraine n'est plus un luxe réservé aux seuls géants du Web.
Sécurité absolue et souveraineté sans dépendance au cloud
Mais au-delà des économies, c'est la maîtrise totale de vos actifs numériques qui devient le véritable enjeu stratégique.
L'avantage critique du zéro fuite de données
Le confinement des données dans votre réseau interne change tout. Passer par des API tierces expose votre propriété intellectuelle à des risques majeurs. En restant local, vous verrouillez vos secrets industriels. C'est une barrière physique infranchissable pour l'extérieur.
La conformité au RGPD devient enfin simple et naturelle. L'IA locale assure qu'aucune information sensible ne franchit vos murs. Vous éliminez d'office les transferts de données transfrontaliers problématiques.
Vous gagnez une indépendance totale face aux géants du cloud. Plus de pannes de services externes ou de hausses tarifaires soudaines. Vous reprenez le volant de votre infrastructure technique dès aujourd'hui.
L'architecte au service de votre infrastructure locale
Mon rôle consiste à intégrer ces modèles compressés avec précision. J'adapte l'intelligence artificielle sur vos serveurs pour garantir une efficacité maximale. Chaque paramètre est ajusté pour votre environnement spécifique.
Nous transformons votre matériel actuel en un véritable atout stratégique. Inutile de racheter des clusters GPU coûteux. Nous optimisons l'existant pour libérer sa puissance.
Critère | IA Cloud Classique | IA Locale TurboQuant | Bénéfice Client |
|---|---|---|---|
Confidentialité | Limitée | Totale | Risque zéro |
Latence | Variable | Faible | Réactivité accrue |
Coût récurrent | Élevé | Nul | Budget maîtrisé |
Dépendance | Forte | Nulle | Souveraineté |
Personnalisation | Standard | Élevée | Sur-mesure |
Je garantis une mise en œuvre rapide et fluide. Votre IA devient opérationnelle, privée et sécurisée en un temps record.
Puissance de calcul brute sur votre matériel standard en 2026
En fait, cette souveraineté ne sacrifie en rien la performance, bien au contraire, les chiffres de 2026 sont sans appel.
Des gains de vitesse concrets sur nvidia h100
L'accélération des calculs sur les puces NVIDIA atteint des sommets. TurboQuant réduit la latence de réponse de manière drastique. Les interactions deviennent quasi instantanées pour l'utilisateur final. Le matériel n'est plus un frein à l'usage.
Le traitement des logs d'attention s'envole littéralement. Les modèles ne stagnent plus lors des phases de réflexion intenses. On observe une fluidité totale même sur des contextes longs.
L'efficacité énergétique progresse aussi. Moins de cycles inutiles signifie une facture d'électricité réduite.
Latence divisée par 3
Débit de tokens doublé
Stabilité thermique
La force de l'open-source avec llama.cpp et mlx
La communauté adopte massivement TurboQuant pour briser les barrières. Des bibliothèques comme llama.cpp et MLX intègrent déjà ces avancées majeures. Chaque développeur peut désormais exploiter cette puissance brute.
L'accessibilité sur les machines de bureau change la donne. Une simple station de travail bien équipée peut désormais rivaliser avec des serveurs d'hier. Plus besoin de clusters GPU géants.
Vous profitez des meilleures innovations mondiales sans verrouillage. L'écosystème ouvert garantit une liberté totale face aux logiciels propriétaires coûteux.
L'IA de pointe est désormais à la portée de chaque bureau. La démocratisation de la puissance est enfin une réalité concrète.
TurboQuant Google révolutionne l'IA On-Premise en divisant par six l'empreinte VRAM via une compression extrême du cache KV. Optimisez dès maintenant vos serveurs existants pour garantir une souveraineté totale et des performances décuplées. Transformez votre infrastructure actuelle en un moteur de calcul d'élite pour dominer l'ère de l'IA locale.
FAQ
Qu'est-ce que la technologie TurboQuant développée par Google ?
TurboQuant est une solution de compression extrême conçue par Google Research pour optimiser les grands modèles de langage (LLM). Elle repose sur deux piliers techniques : PolarQuant, qui convertit les données en coordonnées polaires, et l'algorithme Quantized Johnson-Lindenstrauss (QJL). Cette combinaison permet de réduire drastiquement l'empreinte mémoire des modèles sans sacrifier leur précision ni nécessiter de réentraînement complexe.
Comment TurboQuant résout-il le problème de la saturation de la mémoire VRAM ?
Le principal frein à l'IA locale est le goulot d'étranglement du cache clé-valeur (KV), qui sature rapidement la mémoire vidéo (VRAM) lors de contextes longs. TurboQuant compresse ce cache jusqu'à 6 fois, permettant à des modèles ultra-performants de fonctionner sur du matériel standard. En passant à une quantification de seulement 3 ou 4 bits, on libère l'espace nécessaire pour traiter des documents volumineux ou des conversations complexes sans investir dans des clusters GPU inaccessibles.
Quels sont les gains de performance concrets sur les serveurs actuels ?
L'utilisation de TurboQuant transforme radicalement la vitesse de traitement. Sur des accélérateurs comme le NVIDIA H100, on observe une accélération allant jusqu'à 8 fois pour le calcul des logits d'attention. Pour l'utilisateur, cela se traduit par une latence divisée par trois et une fluidité quasi instantanée, rendant l'IA souveraine aussi réactive, sinon plus, que les solutions cloud propriétaires.
Pourquoi l'IA locale devient-elle plus accessible pour les entreprises ?
Grâce à cette compression extrême, le ticket d'entrée financier s'effondre. Les entreprises peuvent désormais exploiter leurs infrastructures existantes et des stations de travail classiques pour faire tourner des modèles experts comme Gemma ou Mistral. Cette démocratisation permet aux PME de bénéficier d'une IA de pointe tout en garantissant une souveraineté totale des données, en accord avec les exigences du RGPD, sans dépendre des tarifs ou des pannes des géants du cloud.
Cette technologie est-elle déjà disponible pour les développeurs ?
Absolument. L'écosystème open-source a déjà commencé à intégrer ces avancées. Des bibliothèques populaires comme llama.cpp et MLX (pour les puces Apple Silicon) explorent et implémentent ces méthodes de quantification. Cela signifie que les outils pour déployer une IA locale, performante et sécurisée sur votre parc informatique actuel sont déjà à portée de main.